
My profound thanks go to budding commercial digital artist and alround genius, Tim Kaiser. His tireless efforts over the past few weeks have produced the three pictorial metaphors (including the banner) I commissioned which go above and beyond specifications

 Embarking on a public writing career in 2004, I began by (often positively) vexing other message boards with extended expansive comments in response to circulars. After almost a decade it became clear the style was too volatile for that medium. Hence it so happens that this website is testament to my first (and perhaps dying) effort at amateur journalism. By way of due diligence, I did initially approach others for feedback. Upon primary inspection of the “blog”, a Facebook acquaintance sneered of it “well, it’s opinion, I suppose”. Of course that was loaded sentiment offered by someone notably aggravated by my stance on things in general and, as such, the statement was salaciously unfair. Being anti-populism, I am destined to offend which means there are many who will find my special touches distasteful.
Embarking on a public writing career in 2004, I began by (often positively) vexing other message boards with extended expansive comments in response to circulars. After almost a decade it became clear the style was too volatile for that medium. Hence it so happens that this website is testament to my first (and perhaps dying) effort at amateur journalism. By way of due diligence, I did initially approach others for feedback. Upon primary inspection of the “blog”, a Facebook acquaintance sneered of it “well, it’s opinion, I suppose”. Of course that was loaded sentiment offered by someone notably aggravated by my stance on things in general and, as such, the statement was salaciously unfair. Being anti-populism, I am destined to offend which means there are many who will find my special touches distasteful.
For the record, all journalists offer opinions whether these are their own or rebranded viperous propagandas. Taking “crime” as the example, a policeman invariably doesn’t know the pattern of events leading to an infraction. Instead, he tries to best guess with authoritative bias. Therefore those “style” of reflective reports are tainted from outset, most particularly when the journalist presumes any authority issues word of God. To be clear, I do not personally offer opinion, but my deeply human style of writing lends to presenting truth so compellingly, it is as though my output transcends reality. Rather than looking for concrete agents to discredit truth, my critics prefer direct slander or hurling unsanitary insults at me.
 Fantasy it must be said also transcends reality. Whilst I feel he doesn’t fully appreciate the scope or power of imagination, Jon Rappoport has made a career from scripting exercises geared to coaxing make-believe into being. I make no secret of the fact I enjoy his writing and his extraordinary intellect. When not distracted by corporate alliances, he is one of the best journalists on the net. Jon takes a very special interest in the manipulation of healthcare, but he tends to follow the shady “statistics” path. Accountability is the first weapon of propagandists. Who could possibly dispute “official figures”?
Fantasy it must be said also transcends reality. Whilst I feel he doesn’t fully appreciate the scope or power of imagination, Jon Rappoport has made a career from scripting exercises geared to coaxing make-believe into being. I make no secret of the fact I enjoy his writing and his extraordinary intellect. When not distracted by corporate alliances, he is one of the best journalists on the net. Jon takes a very special interest in the manipulation of healthcare, but he tends to follow the shady “statistics” path. Accountability is the first weapon of propagandists. Who could possibly dispute “official figures”?
Given my rather zany approach to serious news worthy topics, though I had conceptualised “Coming Clean on Cancer” back in 2016, for two long years I struggled to put words to ambition. Applying frivolity to something as sombre as cancer perhaps equates to mixing all colours in a forlorn attempt to create white. There are many compelling theories that will never practically move a harmonised audience. Even so, given the generous reception to my announced intentions all that time ago, it seemed clear that this, of all titles, could actually engage populist interest in me and my website. I desperately need a numbers’ boost if my work is going to have any longevity. Hindering the objective in relation to “Coming Clean on Cancer” is an enormous roadblock. The critical problem is I neither have direct conventional experience as physician nor scientist, so how am I qualified to discuss serious matters in conjunction with terminal illness?
 Dependent humans insist on being lectured by credentialed mentors. Doubtlessly that is why Jon Rappoport religiously adopts the verified statistics route when discussing professional topics. Nevertheless, configured notions that reduce “amateur” status to abject worthlessness (when compared against “specialists”) are a misnomer. Likewise, those that parasite off misleading or ill applied authoritative statistics will never be able to justify their sewing of deceit. Jon, of all people, should know that the establishment does its upmost to put the kibosh on any true pioneering spirit. Recalcitrant amateur free thinkers produce the bulk of ideas, of which some are quietly adopted by those that lead social peer groups. That is predominantly also why methods applied to analysis, prognoses and theoretical conclusions that consolidate mundane convention rarely diverge much. Suffice to say; though innovative reviews should be welcomed as “breaths of fresh air”, I fear my sparks will do little more than vulgarly confronting stale, sceptical reactions from faithless brethren.
Dependent humans insist on being lectured by credentialed mentors. Doubtlessly that is why Jon Rappoport religiously adopts the verified statistics route when discussing professional topics. Nevertheless, configured notions that reduce “amateur” status to abject worthlessness (when compared against “specialists”) are a misnomer. Likewise, those that parasite off misleading or ill applied authoritative statistics will never be able to justify their sewing of deceit. Jon, of all people, should know that the establishment does its upmost to put the kibosh on any true pioneering spirit. Recalcitrant amateur free thinkers produce the bulk of ideas, of which some are quietly adopted by those that lead social peer groups. That is predominantly also why methods applied to analysis, prognoses and theoretical conclusions that consolidate mundane convention rarely diverge much. Suffice to say; though innovative reviews should be welcomed as “breaths of fresh air”, I fear my sparks will do little more than vulgarly confronting stale, sceptical reactions from faithless brethren.
Many teachers are press ganged into feigning expert status. Were any to tackle the volatile topic “cancer”, I feel sure that, instinctively, condemned-in-waiting would be lulled into pretending they were serious hobby doctors or technicians on the fringes of medical science. Astute Disraeli was prophetically poignant in his muse “there’s lies, there’s damned lies and then there’s statistics”. You see, the problem is that science uses statistics to cultivate determinism. Statistics are meaningless without plans of attack. Scientific goals are brought to life with data. Of course, any discovery tour would do more to impede conclusions than amplify them. That is why a preliminary thesis might be written for investigation to exclusively source “proof”. A modern, blustering vicious cycle of ignorance bungles science bluff. That is until prior valued methods or products mysteriously “fail”. How could the statistics be wrong? Maybe we should ask Mr Disraeli.
 Personally not intending to fall for vanity, if ideas and explanations presented this article don’t resonate because they do not concur with established norms, I don’t care. I will not pretend to be an adjunct of the system or some loopy alternative “quack” simply to foster moronic popularity. It is abhorrently clear to me that conventional sciences, applicable medical strategies and, indeed, physicians themselves have no understanding of what cancer is. Ignorance is deep rooted. They do manage to incessantly admonish uncontrollable, ever present symptoms with such fervent zeal, I feel sure the Papacy is brought to shame by their candour. Such is the momentum, the vacuum precipitates with ceaseless and often dishonourably prejudicial accusations supporting “causes” to the detriment of reason. Whether that be specifically anti-vaccines, cigarettes or generally against ambiguous “carcinogens” depends on the vigour of focused political interests.
Personally not intending to fall for vanity, if ideas and explanations presented this article don’t resonate because they do not concur with established norms, I don’t care. I will not pretend to be an adjunct of the system or some loopy alternative “quack” simply to foster moronic popularity. It is abhorrently clear to me that conventional sciences, applicable medical strategies and, indeed, physicians themselves have no understanding of what cancer is. Ignorance is deep rooted. They do manage to incessantly admonish uncontrollable, ever present symptoms with such fervent zeal, I feel sure the Papacy is brought to shame by their candour. Such is the momentum, the vacuum precipitates with ceaseless and often dishonourably prejudicial accusations supporting “causes” to the detriment of reason. Whether that be specifically anti-vaccines, cigarettes or generally against ambiguous “carcinogens” depends on the vigour of focused political interests.
A recent article on another website of mine makes for a good investigative guinea pig. Content, some may determine, presents little more than dubious information. This is because the case I make confidently flies in the face of traditional authority. There is a notable absence of essential proof. The essence of subject matter gravitates around philosophies over human’s paradoxical status demarked by the cerebral cortex and its conflicting alliance with the so-called reptilian brain. Ironically, content observes other worldly “reptilians” (some believe act as shadowy pseudo overlords) use consensus view to control humanity. Whether this prognosis is correct or not does not tarnish the reality. Consensus view syndrome is so prolifically acute, just about everyone is severely infected. Popular opinions largely serve as “truths”. Statistics punctuate consensus output. “Proof” is a control mechanism because “evidence” (sic) must be backed by statistics if it is to be accorded.
 Coming down to Earth, I concur that statistics do account for replication and these could be beneficial to truth depending on how investigations were conducted. Current testing is always unaccountably spectral. By that I mean favour towards the way things are done “justifies” procedures, processes and methods. Science experiments are formulated in laboratories. Why not sewers? I remember the history of an absurd test designed to determine how much electricity will kill a human. A rigged telephone system delivered the fatal result to an unsuspecting individual. It was presumed that trial and error is ample enough to divine precise dosages for posterity. Yet, what if breaches of circumstances were to shatter all goals? Science had to rewrite everything it “knew” about radiation after Chernobyl. Reality is never precise. It is always gnarled. For every rule there seems to be at least one exception, sometimes many.
Coming down to Earth, I concur that statistics do account for replication and these could be beneficial to truth depending on how investigations were conducted. Current testing is always unaccountably spectral. By that I mean favour towards the way things are done “justifies” procedures, processes and methods. Science experiments are formulated in laboratories. Why not sewers? I remember the history of an absurd test designed to determine how much electricity will kill a human. A rigged telephone system delivered the fatal result to an unsuspecting individual. It was presumed that trial and error is ample enough to divine precise dosages for posterity. Yet, what if breaches of circumstances were to shatter all goals? Science had to rewrite everything it “knew” about radiation after Chernobyl. Reality is never precise. It is always gnarled. For every rule there seems to be at least one exception, sometimes many.
Methodical study should take note of this. Would scientists ever consider the internal or external energetic status of experimentation environments? How much does ephemeral resonance implicate material reality?
 The creators of the first atomic bomb believed that the domino effect from impairing a single particle would “theoretically” collapse all matter in the universe. Here, for once, “science” at least showed tentative respect for the machinations of existence. Of course atoms are not solid and scientists should consider this carefully. But for circumstantial perception, quantum components would have zero mass. Indeed, was it not for the way they are perceived, they would not exist at all. That makes the truth a materialist’s worst nightmare. Atoms act as catalysers for “the other side” (that which doesn’t exist) facilitating an unbreakable communication tendered between receptively dimensional experiencers and (for lack of better terminology) “God”. The connection is all powerful as it determines form. Values that permit existential parameters are unbreakable. Humans of normal capacity are little more than configured “witnesses” and that’s why rudimentary sciences obsess over material symptoms.
The creators of the first atomic bomb believed that the domino effect from impairing a single particle would “theoretically” collapse all matter in the universe. Here, for once, “science” at least showed tentative respect for the machinations of existence. Of course atoms are not solid and scientists should consider this carefully. But for circumstantial perception, quantum components would have zero mass. Indeed, was it not for the way they are perceived, they would not exist at all. That makes the truth a materialist’s worst nightmare. Atoms act as catalysers for “the other side” (that which doesn’t exist) facilitating an unbreakable communication tendered between receptively dimensional experiencers and (for lack of better terminology) “God”. The connection is all powerful as it determines form. Values that permit existential parameters are unbreakable. Humans of normal capacity are little more than configured “witnesses” and that’s why rudimentary sciences obsess over material symptoms.
Symptoms, I have stated many times before, are either in deference to or at loggerheads with causes. Medically, the culprit of any knife wound is self-explanatory. That fits in with science etiquette, though is it the wielder or implement that actually cause an injury? Microbial conditions are much harder to evaluate. These potentially implicate energetic resonance under such conditions whereby irrational meanderings might appeal to the rational. Interestingly, the key to understanding why remarkably coincides with determining what nothing “is”. Ancient Romans, for instance, had no digit for zero. From this I judge they were incredibly astute. Voids expose gaping weaknesses of our sciences. That is because, from the materialistic perspective, “nothing” can only ever be paraphrased theoretically or philosophically.
 Due to physical limitations, complicated machines are used to test the efficacy of beliefs, but even these can only evaluate something. For instance, is a vacuum truly a vacuum or does existence replace each emptiness with miracles? Could “something” incongruously exist perpetually beyond detection in place of what is believed to be nothing? Here science would do well to come to terms with how Einstein’s opinions on relative time dilation present clues to the truth. How does time “work” in conjunction with the experiential atomic universe? These questions need to be answered effectively before an appreciation of the consuming complexity of cancer can be tendered with any sense of comprehension. That is one of the primary reasons I have been reluctant to tackle the subject until now.
Due to physical limitations, complicated machines are used to test the efficacy of beliefs, but even these can only evaluate something. For instance, is a vacuum truly a vacuum or does existence replace each emptiness with miracles? Could “something” incongruously exist perpetually beyond detection in place of what is believed to be nothing? Here science would do well to come to terms with how Einstein’s opinions on relative time dilation present clues to the truth. How does time “work” in conjunction with the experiential atomic universe? These questions need to be answered effectively before an appreciation of the consuming complexity of cancer can be tendered with any sense of comprehension. That is one of the primary reasons I have been reluctant to tackle the subject until now.
 The way time is structured impacts reality more than routine sciences would possibly ever consider. Thorough effects of time dilation have mostly been ignored, partly because cursory distortion reveals the metaphysical is superimposed under and over physicality. An undeniable observation in relation to this is, though chronology is implicitly linked to perception; the syndrome extends well beyond agreeable reality. Every physical thing located in domains comprising human dimensional bandwidth is subject to a relatively consistent set of rules that define and govern “aging”. Universal consistencies, it must be emphasised, give materialism intellectual credibility. However the paradox of spontaneous creation becomes unarguable evidence supporting a non-physical divine planner’s role in crafting a constructive blueprint. In this instance “a” divine planner may be construed as “many” diverse agents “working in unison” towards common interests.
The way time is structured impacts reality more than routine sciences would possibly ever consider. Thorough effects of time dilation have mostly been ignored, partly because cursory distortion reveals the metaphysical is superimposed under and over physicality. An undeniable observation in relation to this is, though chronology is implicitly linked to perception; the syndrome extends well beyond agreeable reality. Every physical thing located in domains comprising human dimensional bandwidth is subject to a relatively consistent set of rules that define and govern “aging”. Universal consistencies, it must be emphasised, give materialism intellectual credibility. However the paradox of spontaneous creation becomes unarguable evidence supporting a non-physical divine planner’s role in crafting a constructive blueprint. In this instance “a” divine planner may be construed as “many” diverse agents “working in unison” towards common interests.
An arbitrary existence would have no laws or, rather, laws would be irregularly and inconsistently incidental. Yet if human could uncouple from perception and time, then the way existence “works” would change irrevocably. Einstein theorised that time slows at speed (relative to the external). His equation measurement curves designed to demonstrate the fact are infamous. Expanding this view (with tinges of Irony), relative to all other things, everything physical has momentum, even if perception pre-judges “stillness” or lifelessness as valid scenarios. If zero momentum could really be achieved, then time would be absolute, so pure stillness would possibly generate existence out-of-existence because of the necessary uniformity. Vibrational string theory more or less verifies this truth. Physical existence at the base level consists only of particles in constant variable wave formations.
 The one thing that could possibly harmonise absolute time is nothing and. therefore, nothing cannot exist, or, better still, perhaps this might equate to the “summary of everything” – theoretical dimension ten. Before I address the conundrum more coherently, I should like to add that light takes no time to reach its destination, contradicting mundane science opinion. Apparent time dilation highlights impair of the human perception response. That damage is acute. Our acrid boast that the sun’s rays take four whole minutes to travel a cosmic nanometre to Earth exposes a gaping deficiency. How far adrift of reality are we over a cosmic light year? What explains the discrepancy between perception and reality should be science quest number one.
The one thing that could possibly harmonise absolute time is nothing and. therefore, nothing cannot exist, or, better still, perhaps this might equate to the “summary of everything” – theoretical dimension ten. Before I address the conundrum more coherently, I should like to add that light takes no time to reach its destination, contradicting mundane science opinion. Apparent time dilation highlights impair of the human perception response. That damage is acute. Our acrid boast that the sun’s rays take four whole minutes to travel a cosmic nanometre to Earth exposes a gaping deficiency. How far adrift of reality are we over a cosmic light year? What explains the discrepancy between perception and reality should be science quest number one.
It seems obvious to me that the culprits are those nefarious atoms I introduced earlier. Late nineteenth century two slit experiment (as crudely as it was directed) provides great insight here. Atoms appear to generate potentially unlimited congruous reality standards (again confirming string theory). Thus, subjective laws governing this dimension present an illusion that is scripted. In other words, limited experiencers dial into the script which is delivered by atoms. Therefore it doesn’t need a genius to correlate that time (as a cosmic script) could be used to manipulate “reality” by powers with essential knowledge, tools and ability. That is why certain converging dimensional circumstances are able to defy standardised sense of reality. Historic scenes mysteriously morphing into existence (be it some instances are proto-physical or ghostly) are the most sensational examples of these sorts of phenomena.
 Those with the power to manipulate would have to comprehend the critical role atoms have to play in fabricating everything. Thus, these minute particles are not merely arbitrary figments designated to hinder comprehensive understanding of important, busy physicists. Without them there would be nothing for physicists to witness, so they cannot be avoided. Routine arrogance and presumptive bias summarises limited devotion to quantum illumination. Experiments are conducted in the usual way. Imperialists have been determined to solidify even the most microscopic components of the universe from the very outset. It seems to me that the strategy was “long view”, designing a dastardly operational manual. Planning, it should be highlighted, perfectly casts the supplementary objective equating to ramming square peg into round hole.
Those with the power to manipulate would have to comprehend the critical role atoms have to play in fabricating everything. Thus, these minute particles are not merely arbitrary figments designated to hinder comprehensive understanding of important, busy physicists. Without them there would be nothing for physicists to witness, so they cannot be avoided. Routine arrogance and presumptive bias summarises limited devotion to quantum illumination. Experiments are conducted in the usual way. Imperialists have been determined to solidify even the most microscopic components of the universe from the very outset. It seems to me that the strategy was “long view”, designing a dastardly operational manual. Planning, it should be highlighted, perfectly casts the supplementary objective equating to ramming square peg into round hole.
Was mankind to evolve, the true purpose of atoms would become common knowledge and for good reason. Notably study of these universal catalysers is crucial if all illnesses are to be neutralised without the need of medicine or operational accoutrements. But is a globalism free of greedy corporate healthcare practical? Perhaps ruling powers would do well to refer to supposed extra-terrestrial entities commonly called “Grey Beings” and related accounts that claim each can “see” a body’s auric field (collective quantum resonance). In doing so, technicians are somehow able to massage cures cancelling infected areas simply by using their extremities (is this what Jesus meant by “the laying on of hands”?). Our sciences must come to terms with the phenomenon somehow if humanity is to progress. Thankfully, in a very minor way, Barbara Brennan has begun the investigative tour and can already demonstrate some pragmatic effects with her adaptation of Reiki techniques.
 Several other theoretical extra-terrestrials use a “standardised” royal electronic wand (attached to low weight backpack) to achieve the same ends as the Grey Beings, although power over life goes both ways here as the device doubles as a potentially lethal laser weapon. I realise my referencing “aliens” is bound to tease the smugness of convention, but that which is relevant must be reviewed if honest dedication to discovery of truth is to be commuted. Alien is the fancy word for unknown. Few credibly dispute the apparent existence of entities that have yet to garnish formal identity. Certainly, in most cases, identified attributes suggest existences beyond physical. Some reliable accounts have only been made possible through mediums such as regressive hypnosis. It seems these strange beings can infiltrate dreams. Psychology has never deliberately clarified whether dreamscape is a different form of reality or random mind offcuts.
Several other theoretical extra-terrestrials use a “standardised” royal electronic wand (attached to low weight backpack) to achieve the same ends as the Grey Beings, although power over life goes both ways here as the device doubles as a potentially lethal laser weapon. I realise my referencing “aliens” is bound to tease the smugness of convention, but that which is relevant must be reviewed if honest dedication to discovery of truth is to be commuted. Alien is the fancy word for unknown. Few credibly dispute the apparent existence of entities that have yet to garnish formal identity. Certainly, in most cases, identified attributes suggest existences beyond physical. Some reliable accounts have only been made possible through mediums such as regressive hypnosis. It seems these strange beings can infiltrate dreams. Psychology has never deliberately clarified whether dreamscape is a different form of reality or random mind offcuts.
The reluctance to go discover has reached epidemic proportions because every human (attached to civilisation) has been systemised in one way or another. Prior to the onset of “television”, passage rites were contests between families and schools. Today we are literally bombarded with different opinions from all sides. Most viewpoints have little or no bearing on raw truth. They pitch (sell) ideals. Therefore it is important to give an example that demonstrates how people (including conventional scientists) are programmed to think. Historians promote British and subsequent American abolition of slavery as one of the greatest virtuous achievements of commercial government, yet the reverse is true. When Britain amended the 1807 Slave Trade Act in 1833 effectively making sale/purchase of humans’ obsolete, reasoning was not supported by philanthropic goodwill. The prior (eighteenth) century had gone through a specular commodities boom/bust that incurred a mighty stock market crash affectionately called the “South Sea Bubble”. One of the reasons for the bust was the lack of buyers for exotic merchandise.
 Buffering against much protest and suffrage of the people, the known world began to change from 1780 onwards because business embarked on a shift from local craft industries to larger scale grouped commercial operations. Things demonstrably reached a head with Luddite attacks on Manchester (England) cotton weavers for using automatic looms. Therefore it is plain to see that the real reason for the abolition of slavery was the emerging industrial revolution and its associated exaggerated labour contingent requirement. There is a partnering myth (in conjunction with the rise of the industrialists) that deserves exploding. Prior Machiavellian craftsmen did not take umbrage at any loss of work, although their incomes did more than supplementing survival by now. No, big business stole their power.
Buffering against much protest and suffrage of the people, the known world began to change from 1780 onwards because business embarked on a shift from local craft industries to larger scale grouped commercial operations. Things demonstrably reached a head with Luddite attacks on Manchester (England) cotton weavers for using automatic looms. Therefore it is plain to see that the real reason for the abolition of slavery was the emerging industrial revolution and its associated exaggerated labour contingent requirement. There is a partnering myth (in conjunction with the rise of the industrialists) that deserves exploding. Prior Machiavellian craftsmen did not take umbrage at any loss of work, although their incomes did more than supplementing survival by now. No, big business stole their power.
Therefore the advantages gained from abolition of slavery were numerous. Firstly it ensured labour surpluses so wages needed to be no greater than rock bottom. Secondly it removed the obligation to provide social security to those displaced by consequence of war and so forth. Thirdly there was a potentially unlimited stock of hands to oil automated enterprises
 1865 abolition in America not-so-mysteriously prompted a European cotton price hike. The new cost of each bale had risen fivefold courtesy of the paid plantation labour contingent. Now lucrative cargos that had once been worthless were subject to duty, currency charges and insurance. This ultimately was the reason for huge cotton wholesale price increases without notice. Messieurs Rothschild and company were that pleased with results in Manchester; they erected a commemorative statue in 1875. The industrial revolution did pre-empt thriving populaces, but concessions came at a dear price. Constant and lasting recessions from the early nineteenth century restricted the GDP. Initially the incubus of mass production only provided a means for skilled labourers. Prior slaves (euphemistically labelled servants) and unskilled were left to fend for themselves. Predictably transposition fostered a spike in survival “crimes” (theft of foods and so on) which reached epidemic proportions by the 1850’s and ‘60’s. That is why historians herald the industrial revolution as “saving poverty”, but it is actually one of great lies. Sadly deceit cements popular knowledge which fortifies the human condition of intellectual apathy.
1865 abolition in America not-so-mysteriously prompted a European cotton price hike. The new cost of each bale had risen fivefold courtesy of the paid plantation labour contingent. Now lucrative cargos that had once been worthless were subject to duty, currency charges and insurance. This ultimately was the reason for huge cotton wholesale price increases without notice. Messieurs Rothschild and company were that pleased with results in Manchester; they erected a commemorative statue in 1875. The industrial revolution did pre-empt thriving populaces, but concessions came at a dear price. Constant and lasting recessions from the early nineteenth century restricted the GDP. Initially the incubus of mass production only provided a means for skilled labourers. Prior slaves (euphemistically labelled servants) and unskilled were left to fend for themselves. Predictably transposition fostered a spike in survival “crimes” (theft of foods and so on) which reached epidemic proportions by the 1850’s and ‘60’s. That is why historians herald the industrial revolution as “saving poverty”, but it is actually one of great lies. Sadly deceit cements popular knowledge which fortifies the human condition of intellectual apathy.
Political “chess moves” that design information flows have corrupted all sciences by some means, including those apparently devoted to medical research. Quintessential technicians’ priority aim is to debunk any anomaly contradicting political etiquette. Other than consultative psychology, mainstream primary healthcare used to branch into two distinct paths: pharmaceutical and butchery, but now a few alternative remedial techniques (such as acupuncture) are creeping in mainly to satisfy burgeoning traditional Chinese markets for that economy’s nouveau riche. On current course, there is nowhere near enough momentum for transition to kinetic healing. Supposed extra-terrestrial methods will not be adopted by the mainstream unless that hand is forced. Scientists seem much better adapted to deliver confusion that scorns honest debate (geared to keeping the riff-raff out, of course). Consequentially quantum determinations are a disaster area. Beyond vague conceptualisation of string theory, physicists are clueless. Quantum, suffice to say, has no current bearing on healthcare at all, when it should.
 Back in the 1930’s professionals heralded Royal Rife’s electron microscope as the absolute victor (from memory 1932, to be precise) in the war on cancer. Cancer under this mechanism, to all intents and purposes, had been “cured” right up until the pharmaceutical lobby learned of the threat to their financial ambitions. Rife was then ridiculed by the establishment’s dramatic change of heart, his machine destroyed and blueprints lost. Even so, attesting modern day tolerance towards remedial solutions, a variation of the microscope has found its way into certain veterinary clinics. Though it doesn’t expose the quantum layer, the device will identify individually marked cancer cells, which is the benefit. Rogue agents are correctively zapped with light electric charges. This is still nothing more than cosmetic “symptom adjustment” in motion, but, at least, small steps forward are the ones needed for full visionary conversion to quantum healing to eventuate.
Back in the 1930’s professionals heralded Royal Rife’s electron microscope as the absolute victor (from memory 1932, to be precise) in the war on cancer. Cancer under this mechanism, to all intents and purposes, had been “cured” right up until the pharmaceutical lobby learned of the threat to their financial ambitions. Rife was then ridiculed by the establishment’s dramatic change of heart, his machine destroyed and blueprints lost. Even so, attesting modern day tolerance towards remedial solutions, a variation of the microscope has found its way into certain veterinary clinics. Though it doesn’t expose the quantum layer, the device will identify individually marked cancer cells, which is the benefit. Rogue agents are correctively zapped with light electric charges. This is still nothing more than cosmetic “symptom adjustment” in motion, but, at least, small steps forward are the ones needed for full visionary conversion to quantum healing to eventuate.
 In respect to cancer, current mainstream tradition is to either poison (chemo) or butcher (cut out) malignant tumours. Nevertheless, when thinking laterally, electric microscope innovation is no different than the occurrence of x-ray scanners, which have opened up visibility of the internal body. The microscopic approach allows professionals to drill down and inspect the detail. The more detail, the greater the clarity and drill down some more to the ultra-microscopic, well then absolute detail and the discovery of a canopy of complaint root causes waits. Of course this lends to interpretive skills and diagnosis needing to become radically intuitive. Surely that is a small price to pay for the cessation of all disease?
In respect to cancer, current mainstream tradition is to either poison (chemo) or butcher (cut out) malignant tumours. Nevertheless, when thinking laterally, electric microscope innovation is no different than the occurrence of x-ray scanners, which have opened up visibility of the internal body. The microscopic approach allows professionals to drill down and inspect the detail. The more detail, the greater the clarity and drill down some more to the ultra-microscopic, well then absolute detail and the discovery of a canopy of complaint root causes waits. Of course this lends to interpretive skills and diagnosis needing to become radically intuitive. Surely that is a small price to pay for the cessation of all disease?
Unfortunately it becomes fervently clear to those with vision, Krishna’s prophetic “forces of evil paralyse” was aimed at peer groups, such as those currently throttling medical renaissance, In absence of altruism, warding off the discovery tour in order to facilitate (quite frankly) satanic conventions is the primary agenda of institutional practices. All conventions are satanic, no matter how apparently viscerally virtuous, because they deny progressivism. Progressivism predicts the creative path. Reflecting Einstein’s wisdom, censorship belies insane stagnation. Medicine, consequentially, has been confined to a very narrow forked path, one that is “shielded” from competition. Medicine is no longer about healthcare. It has become a facet of commerce conducted exclusively in the interest of financial profits. Whether those are generated by honest means, bogus insurance or hidden “tax dollars” is immaterial.
 It should be abruptly clear that comparable political strategies used by the filthy oil industry to oust clean energy solutions are casually applied to healthcare. This fact is more than amply alerted by the narcissistic Cancer Council’s determined rebuke of any solution that defies authoritative “status-quo”. The “system” (defining the forked path) is limited to contributions that should only butcher or poison. Chinese remedial medicine is dressed as nothing more than a “fad” in my opinion, which generally mimics how spectral social “solutions” are handled by government. Approaches, where possible, are limited to acts of war. Eradication is the permanent ideal and the staple for “problem, reaction, solution”. Attributed laws act as corresponding vanguard for that apex of control.
It should be abruptly clear that comparable political strategies used by the filthy oil industry to oust clean energy solutions are casually applied to healthcare. This fact is more than amply alerted by the narcissistic Cancer Council’s determined rebuke of any solution that defies authoritative “status-quo”. The “system” (defining the forked path) is limited to contributions that should only butcher or poison. Chinese remedial medicine is dressed as nothing more than a “fad” in my opinion, which generally mimics how spectral social “solutions” are handled by government. Approaches, where possible, are limited to acts of war. Eradication is the permanent ideal and the staple for “problem, reaction, solution”. Attributed laws act as corresponding vanguard for that apex of control.
Underlying belief presumes majorities would routinely select “peace” over challenging the perceived might of great government. This has most definitely been proven true. I find no evidence of genuine spontaneous revolt on grand scales other than occasional population exoduses. Thus, medicine is rather short on options. “Peace” (ironically) here avails the death of a patient, so “war” is emphatically scripted as the only “solution” option. It is a sort of macabre win/win. Each fallen patient becomes a posthumous soldier for the cause per the concept’s scandalous design. Therefore, any transition to futuristic healthcare is all the more unlikely because effective energetic remedies require a complete absence of tension. Tension, let us be frank, is a prerequisite to ensure conflict eventuates (the limit being unabashed all-out war, of course).
 Background over, it is time for me to attempt to format an outline of what illness is. Findings may require paradigm shifts of thinking. Perhaps I should present my assessment of “gravity” as the preamble here. Vis-à-vis the truth is roughly the opposite of what might generally equate to popular knowledge. Is a door pulled or pushed shut? Is there any way of determining how to distinguish between the two methods? In this case, there is. Causes and effects are always transparent even if the door is automatically powered. But the instance of gravity is far from clear. Prior to defining theses, unseen causes are unknown. Scrutinised effects coordinate presumptions. Beyond any proverbial apple tumbling to the ground of its own accord, we do not know “why” it falls short of applying logic from constructive imagination. Logic, in this instance, reasons an apple is pulled or pushed to the ground by invisible external forces, which are symptomatically labelled “gravity”.
Background over, it is time for me to attempt to format an outline of what illness is. Findings may require paradigm shifts of thinking. Perhaps I should present my assessment of “gravity” as the preamble here. Vis-à-vis the truth is roughly the opposite of what might generally equate to popular knowledge. Is a door pulled or pushed shut? Is there any way of determining how to distinguish between the two methods? In this case, there is. Causes and effects are always transparent even if the door is automatically powered. But the instance of gravity is far from clear. Prior to defining theses, unseen causes are unknown. Scrutinised effects coordinate presumptions. Beyond any proverbial apple tumbling to the ground of its own accord, we do not know “why” it falls short of applying logic from constructive imagination. Logic, in this instance, reasons an apple is pulled or pushed to the ground by invisible external forces, which are symptomatically labelled “gravity”.
Misconstrued magnetism has permitted one of the most monumental physics errors in the history of science. Via a complex network of circumstantial forces originating from a bold inner planetary “sun”, an Earth apple is in fact demonstratively pushed to the ground.
 Applying this Bohemian style of investigation, I can add that all diseases reflect the state of the libido, expanding popularly designated illnesses of the mind. All illnesses stem from the mind’s adjustment to the body. In some instances causes and symptoms are two way cycles, but the bulk of complaints are expressly “arranged” by any libido’s reaction to given sets of circumstance. Symptoms cover up and can actually obfuscate causes. That is why radical changes of environments might ensure miraculous recoveries even against “incurable” conditions. These environmental differences can be subtle or acute. They could be dietary, intellectual or locational. Quintessentially the libido must be unfamiliar enough with new circumstances that a complete review of body autonomy is ignited. From the technical perspective, extreme measures are needed up to a full quantum recalibration (notably in the case of cancers).
Applying this Bohemian style of investigation, I can add that all diseases reflect the state of the libido, expanding popularly designated illnesses of the mind. All illnesses stem from the mind’s adjustment to the body. In some instances causes and symptoms are two way cycles, but the bulk of complaints are expressly “arranged” by any libido’s reaction to given sets of circumstance. Symptoms cover up and can actually obfuscate causes. That is why radical changes of environments might ensure miraculous recoveries even against “incurable” conditions. These environmental differences can be subtle or acute. They could be dietary, intellectual or locational. Quintessentially the libido must be unfamiliar enough with new circumstances that a complete review of body autonomy is ignited. From the technical perspective, extreme measures are needed up to a full quantum recalibration (notably in the case of cancers).
Contrary to popular belief, from the atomic perspective, everyone subject to specific pollution is cancerous. Cell damage and responding tumours are not necessarily apparent “to the eye”, but they may be. Significant effects will prompt an individual to consider seeking diagnosis and medics routinely come involved at the “too late” stages. Even so there are natural cosmetic regeneration solutions. These do not isolate and remove causes, but they can perennially stem symptoms. The most prolific worker I am aware of is cannabis oil. Providing sufficient time is given to administration of treatment, the oil appears to permanently delay most (if not all) cancers. In this case an extended healing term generally runs in excess of fifteen months. Thus cannabis will have much less causal benefit to those late stagers that are indefinitely terminally ill beyond the placebo effect. Belief in the cure underscores the importance of the libido and accompanying energetic harmony, by the way.
 Given the overwhelming significance of environment and attitude towards life, hints that the underlying cause of all illness is mind are already in plain sight. What can be achieved from hypnosis should baffle conventional sciences. However, from the microscopic perspective, there are distinct differences that distinguish various types of body invaders. One of the great medical establishment deceits is to foster the myth that some illnesses might be the result of airborne delivered complaints. I can confirm possibly all micro-particles causing illness are received by air. Why the medical establishment is specifically deceitful here, I can explain.
Given the overwhelming significance of environment and attitude towards life, hints that the underlying cause of all illness is mind are already in plain sight. What can be achieved from hypnosis should baffle conventional sciences. However, from the microscopic perspective, there are distinct differences that distinguish various types of body invaders. One of the great medical establishment deceits is to foster the myth that some illnesses might be the result of airborne delivered complaints. I can confirm possibly all micro-particles causing illness are received by air. Why the medical establishment is specifically deceitful here, I can explain.
Back in the early nineteenth century when industrialists were busily constructing factories which would become the template for the later industrial revolution, peoples local to vicinities became sick from toxic emissions and some died. Even this age had its own brand of philanthropic environmentalists. Correspondingly, there ensued vicious wars of words between do-gooders and colonists for the best part of a century until common sense was drowned out by “progress”. A great deal of effort went into enterprising propagandas that cultivated the philosophy that those affected by pollution were naturally sickly and “would die anyway”. Industrialists, per this maligned reasoning, were evangelised into grotesque saviours.
 The propaganda was so infectiously compelling that industry has been able to remain “blameless” for any pollutants poured into the air, which are normally rated “relatively safe” (according to external supposedly independent arbiters that are actually on the payroll). Environmentalists (that aren’t also paid shills) have generally vigorously disagreed with most pollution “ratings”. However, very few are committed to anything more than window dressing so malignant ignorance reigns. Indeed, it is ignorance that has sadly had the effect of exaggerating palpable damage. Roughly 300,000,000 global road vehicles running 24/7 generate 95% of cancer causing pollution, so theoretically (at least) everyone is to blame for their lot here. Don’t they say, if you make your bed, you must lie in it!
The propaganda was so infectiously compelling that industry has been able to remain “blameless” for any pollutants poured into the air, which are normally rated “relatively safe” (according to external supposedly independent arbiters that are actually on the payroll). Environmentalists (that aren’t also paid shills) have generally vigorously disagreed with most pollution “ratings”. However, very few are committed to anything more than window dressing so malignant ignorance reigns. Indeed, it is ignorance that has sadly had the effect of exaggerating palpable damage. Roughly 300,000,000 global road vehicles running 24/7 generate 95% of cancer causing pollution, so theoretically (at least) everyone is to blame for their lot here. Don’t they say, if you make your bed, you must lie in it!
Resuming my efforts to get down to the nitty-gritty, there are six fundamental causes of Illnesses (categorised by the medical establishment). Living “invaders” are separated out as fungi and bacteria. Non-metabolic extraneous matter causes viruses and cancer, though I potentially disagree with this analysis in some cases. The virus rabies and cognitive Parkinson’s disease greatly intrigue me, for instance. Other causes, though not always specifically termed “illnesses”, are effects of severe wounds to the body and symptoms relaying to the breakdown of mind. Currently in the way medicine works, it is intolerably difficult to separate symptoms from causes. Therefore, without any discernible patterns indicating malignance, physicians are at a loss to origins of aggregated concerns (or, indeed, whether there is a concern at all). Intuitive talents have been known to feel problems long before they occur, yet the greatest medical minds are rendered powerless without review of visible cosmetic effects. They cannot see viruses before symptoms appear. Myth persuades cancers can “arbitrarily” spring up anywhere, so obviously without sound pre-emptive strategies every perspective patient may as well be classed as terminal.
 Tying in with “you are what you eat”, the gut keys in with the mind (hence native Redskins recognised parallel inter-connected pulmonary and nervous systems). It delivers all the body’s nutrients via the bloodstream. Lack of appetite is probably one of the best barometers for illness in general. This is not to say it is possible to cure disease simply by synthesising hunger. No, but progress may be delayed or allayed with appetite because after food is processed, the body has capacity to generate. Illness promotes the opposite effect. Degeneration of life summarises death. Spontaneous growth is the gateway to immortality. Sensationally promoted as adjunct to the battle against cancer, it is well known that smoking the conflicting narcotic cannabis will likely induce sufficient improvement of appetite that makes food intake possible. However there is another problem. Delaying or halting the wasting of muscle tissue requires multiple means.
Tying in with “you are what you eat”, the gut keys in with the mind (hence native Redskins recognised parallel inter-connected pulmonary and nervous systems). It delivers all the body’s nutrients via the bloodstream. Lack of appetite is probably one of the best barometers for illness in general. This is not to say it is possible to cure disease simply by synthesising hunger. No, but progress may be delayed or allayed with appetite because after food is processed, the body has capacity to generate. Illness promotes the opposite effect. Degeneration of life summarises death. Spontaneous growth is the gateway to immortality. Sensationally promoted as adjunct to the battle against cancer, it is well known that smoking the conflicting narcotic cannabis will likely induce sufficient improvement of appetite that makes food intake possible. However there is another problem. Delaying or halting the wasting of muscle tissue requires multiple means.
 Different to other illnesses, cancers seem to dramatically and detrimentally affect metabolism, so consumption of food is not necessarily going to aptly remedy weight loss though, without doubt, intake of nutrients will aid prolonging wasting effects. Probability impresses that, perhaps, under these new environmental conditions, certain foods burn out easily and that is why the body appears to receive no benefit. Therefore, the terminally ill must be prepared to reconfigure dietary set up at the drop of a hat if survival is desired. The list of “cancer fighting” foods is endless, but I would recommend intense extract of ginger and chopped coriander leaves as two of the better detoxifying agents. There is also a Brazilian fruit called soursop. The leaves of the plant are ground into a paste and added to water to make a bitter tea. According to tradition, the beverage has a notorious impact in remedying the effects of non-specific cancers. Remember this is not “the cure”, but, rather, prolonged allayment.
Different to other illnesses, cancers seem to dramatically and detrimentally affect metabolism, so consumption of food is not necessarily going to aptly remedy weight loss though, without doubt, intake of nutrients will aid prolonging wasting effects. Probability impresses that, perhaps, under these new environmental conditions, certain foods burn out easily and that is why the body appears to receive no benefit. Therefore, the terminally ill must be prepared to reconfigure dietary set up at the drop of a hat if survival is desired. The list of “cancer fighting” foods is endless, but I would recommend intense extract of ginger and chopped coriander leaves as two of the better detoxifying agents. There is also a Brazilian fruit called soursop. The leaves of the plant are ground into a paste and added to water to make a bitter tea. According to tradition, the beverage has a notorious impact in remedying the effects of non-specific cancers. Remember this is not “the cure”, but, rather, prolonged allayment.
In conjunction with this overall philosophy, pharmaceutical “colonists” process foods that were once the assets of hereditary medical knowledge. Extracts are given technical names in order to confuse doctors and people over pertinent origins. That is why nature can provide miracle cures. Not only are ingredients that have been processed as pills often widely available in raw form, but they are also far more potent remedies than reduced versions. The myth that medicine is more vital than nature is a hangover from nineteenth century confidence quackery. Once again, the best way of introducing non-invasive medication to the bloodstream is via the gut. In instances where resources for elixirs are difficult to obtain, the pharmaceutical cartel sees its first duty is to profits and not to the overall wellbeing of sick. It is unable to reason the moral duty of care.
 My earlier mentioned lack of appetite being the best barometer for illness can be expanded. I have already illustrated the connection between gut response and metabolism, but there is some other implicating factor that goes beyond physical. Complaints that activate cancers might be regarded as identical to those that show viral effects (classed as “viruses”), but for some sort of unknown catalyser that separates conditional outcomes. Viruses can also be divided up into originally organic or inorganic matter. This might affect prognosis, but because medical science refuses to identify true causes (thus exposing those hallowed industrial polluters) we do not know which specific symptoms are generated by invading metallic, chemical, fossil or extraneous compounds. Organic matter problems are easier to quantitatively decode. Swine flu is undoubtedly caused by particles of faecal residue delivered via the atmosphere. Catchment ranges are local, so giant open vats of body waste fuelled by mega-conglomerate pig farms in New Mexico sensationally only polluted a radial area outwards of around a hundred miles. The rest of out-of-range Americans were safe. European or Australian citizens could have only contracted the New Mexico virus by visiting the catchment zone. Viruses are transmitted body to body one way (although there are numerous potential derivatives).
My earlier mentioned lack of appetite being the best barometer for illness can be expanded. I have already illustrated the connection between gut response and metabolism, but there is some other implicating factor that goes beyond physical. Complaints that activate cancers might be regarded as identical to those that show viral effects (classed as “viruses”), but for some sort of unknown catalyser that separates conditional outcomes. Viruses can also be divided up into originally organic or inorganic matter. This might affect prognosis, but because medical science refuses to identify true causes (thus exposing those hallowed industrial polluters) we do not know which specific symptoms are generated by invading metallic, chemical, fossil or extraneous compounds. Organic matter problems are easier to quantitatively decode. Swine flu is undoubtedly caused by particles of faecal residue delivered via the atmosphere. Catchment ranges are local, so giant open vats of body waste fuelled by mega-conglomerate pig farms in New Mexico sensationally only polluted a radial area outwards of around a hundred miles. The rest of out-of-range Americans were safe. European or Australian citizens could have only contracted the New Mexico virus by visiting the catchment zone. Viruses are transmitted body to body one way (although there are numerous potential derivatives).
 HIV deserves separate analysis, conveniently revealing how viruses are transmitted. First off, HIV does not cause “AIDS”. Horrific medications deliver known symptoms to those diagnosed with HIV and Ebola (in particular). Back in the hay day, prior to the great Thalidomide expose, pharmaceutical cartels were consumed by waging wars against all phantom causes without restriction. Perhaps around 1955 a “vaccine” serum was produced to alleviate polio (even though statistics show the virus was on the decline and about to “burn out” – note to self: which industrial practice was becoming obsolete?). The serum was originally grown in the kidneys of green monkeys and chimpanzees. Because heavily populated cosmopolitan areas of Africa are invariably extremely polluted by unregulated industries, wildlife is bombarded with a constant flow of extraneous particles delivered via the local atmosphere.
HIV deserves separate analysis, conveniently revealing how viruses are transmitted. First off, HIV does not cause “AIDS”. Horrific medications deliver known symptoms to those diagnosed with HIV and Ebola (in particular). Back in the hay day, prior to the great Thalidomide expose, pharmaceutical cartels were consumed by waging wars against all phantom causes without restriction. Perhaps around 1955 a “vaccine” serum was produced to alleviate polio (even though statistics show the virus was on the decline and about to “burn out” – note to self: which industrial practice was becoming obsolete?). The serum was originally grown in the kidneys of green monkeys and chimpanzees. Because heavily populated cosmopolitan areas of Africa are invariably extremely polluted by unregulated industries, wildlife is bombarded with a constant flow of extraneous particles delivered via the local atmosphere.
Chimpanzees and green monkeys uniquely process this pollution to their bodies’ specifications and these viral effects were transmuted to the polio vaccine. Because human bodies are different, the same viral effects were “mutated” as HIV strains. When propagandists recommended polio jabs for “safety” from the late 1950’s and early 1960’s (courtesy of the IMF/WHO two-step, Africa was flooded with tainted stocks up until the late 1980’s), the inoculated received active monkey virus at no extra charge, which, of course, altered to become what is now termed “HIV”. Between humans, HIV could only be transmitted “blood to blood” (even though the complaint is apparently seen in body fluids) commonly hampering habitual needle sharing drug users. Symptoms are over quickly and not severe, perhaps equating to a heavy common cold.
Marketing of the HIV “threat” was a campaign of fear and manipulation against the gullible and just about everyone fell for it. To reinforce truth, causers of all the exaggerated AIDS symptoms were through fault of drugs administered as “solution”, notably failed “chemo” agent AZT. Jon Rappoport builds a stunning case in his book “AIDS Inc.”
 In ancient times remedial healthcare was conducted very differently. Roaming tribes either supported shamans or witchdoctors. Evidence of practices has been vaguely preserved by so-called Third World cultures. Mystic healers will take on the burden of tribes, so some illnesses are treatable by “faith” only. It is through connection with the other side that a spiritual practitioner is able to etch a metaphysical bridge with members that are perhaps not individually accounted for. Upon succinct understanding of the complex transcendental role of atoms, the craft could be demystified. It is perhaps ironic that all cancers are caused by fundamentally corrupt molecules. Molecules combine to makes cells. Cells develop cancerous attributes and these grow into malignant tumours that, prematurely, end life. Primitive cultures enjoy expressing themselves in music and dance. Could certain vibrational (wave) frequencies be the answer to some erstwhile miracle cures?
In ancient times remedial healthcare was conducted very differently. Roaming tribes either supported shamans or witchdoctors. Evidence of practices has been vaguely preserved by so-called Third World cultures. Mystic healers will take on the burden of tribes, so some illnesses are treatable by “faith” only. It is through connection with the other side that a spiritual practitioner is able to etch a metaphysical bridge with members that are perhaps not individually accounted for. Upon succinct understanding of the complex transcendental role of atoms, the craft could be demystified. It is perhaps ironic that all cancers are caused by fundamentally corrupt molecules. Molecules combine to makes cells. Cells develop cancerous attributes and these grow into malignant tumours that, prematurely, end life. Primitive cultures enjoy expressing themselves in music and dance. Could certain vibrational (wave) frequencies be the answer to some erstwhile miracle cures?
Before I outline why pollution causes the errors that grow into life ending tumours, it is important to review the historic account. Because medical science only “rates” symptoms, there is no concrete history verifying the course of cancer. It is possible to piece together a circumstantial picture, so that must suffice in place of clarity. By the year 1905 statisticians were noticing a new aggressive style of “cancer” complaint. Though the identical word in ancient Latin used to describe ulcerous infestations, later period (from the twelfth century if my memory serves me correctly) grotesque swellings associated with bubonic plague and like outbreaks were cordially termed “cankers”.
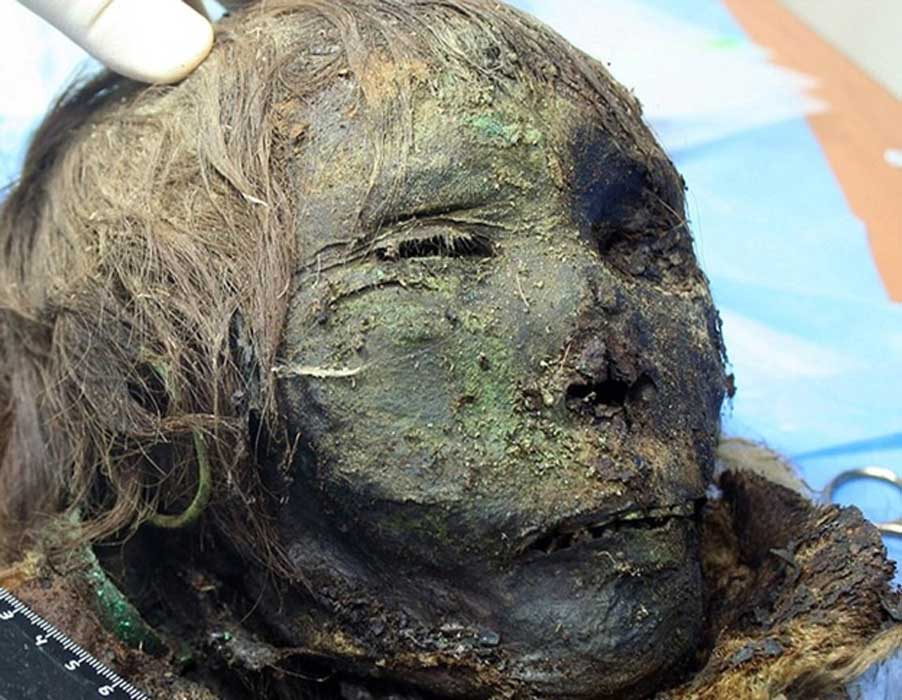 Specific use of cancer re-emerged coinciding with the onset of industrialism. Peer review of historic complaints, such as bloody Queen Mary’s theorised cancer of the womb death in 1558, has been determined by speculations over records. I find it extremely unlikely that Mary actually died of cancer, but she did suffer death and that is all that is certain here. According to my research, no preserved “mummy” has been found to be cancerous either (per modern diagnostic methods). Plausible evidence occurs much later, almost into the modern age. Atmospheric burn off from foundries and other industrial processing facilities contributed to numerous chest infections. But there were other issues too.
Specific use of cancer re-emerged coinciding with the onset of industrialism. Peer review of historic complaints, such as bloody Queen Mary’s theorised cancer of the womb death in 1558, has been determined by speculations over records. I find it extremely unlikely that Mary actually died of cancer, but she did suffer death and that is all that is certain here. According to my research, no preserved “mummy” has been found to be cancerous either (per modern diagnostic methods). Plausible evidence occurs much later, almost into the modern age. Atmospheric burn off from foundries and other industrial processing facilities contributed to numerous chest infections. But there were other issues too.
New found cancer reached epidemic proportions by the 1940’s, at which time around 2% of First World populations suffered attributed ailments. The statistical journey from then on eerily matches the progress of the automobile. Significant benzene tests done just after the Second World War imply the oil business knew what causes cancer as far back as 1950. Given corporate “pharmacy’s” contemptuous disregard of the Hippocratic Oath, it would foolish to cultivate the belief that those wielding overall political power act in the interests of the people. “Big Oil” has used every trick in its arsenal to obfuscate truth ever since straight facts were revealed. One possible ploy is to kill off establishment figures with “cancer” (sic) lulling the gullible into thinking “there is no conspiracy here, because they suffer as much as the rest of us”. Similar tactics (backing off the HIV scam) were used in Third World countries that were offered lucrative IMF underwritten healthcare grants for complaints. Associated doctors were encouraged to record AIDS in place of “unknown causes” deaths in order to maximise IMF investment in fallacy.
 Britain’s coal was a popular alternative home fire food by the late nineteenth century. However, physicians encountered coinciding increases in bronchial conditions. Other less savoury cancer (or cankers) mimicking complaints were recorded too. When greater populations reverted to central heating, the home coal market dwindled, although this does come with a twist of irony. Plants that generate electricity to power heating systems are fuelled by copious quantities of coal. Coal is a type of carbon. Human beings are also made from carbon. Could there be a conflict? Could hard to distinguish differences between types of carbon that have been environmentally mixed corrupt sensitive reproductive systems? Wouldn’t it be paradoxical if there was more to governments’ attack on carbon pollution than meets the eye? Why carbon tax, specifically?
Britain’s coal was a popular alternative home fire food by the late nineteenth century. However, physicians encountered coinciding increases in bronchial conditions. Other less savoury cancer (or cankers) mimicking complaints were recorded too. When greater populations reverted to central heating, the home coal market dwindled, although this does come with a twist of irony. Plants that generate electricity to power heating systems are fuelled by copious quantities of coal. Coal is a type of carbon. Human beings are also made from carbon. Could there be a conflict? Could hard to distinguish differences between types of carbon that have been environmentally mixed corrupt sensitive reproductive systems? Wouldn’t it be paradoxical if there was more to governments’ attack on carbon pollution than meets the eye? Why carbon tax, specifically?
I have gone to great lengths in my effort to illuminate truths about atoms. Here their relationship with cancers will become brutally clear. They may well be contained by unbreakable cosmic laws, but I have also advised existence and reality in general are not as presented by corporate sciences. Perception belies a gnarled and uneven canopy that apparently disguises numerous contradictions (regularly discombobulated as anomalies by science political interests). Carbon, in truth, is one of the greatest enigmas of all. How (on Earth) does it cause cancers? It seems that certain molecule combinations are able to confuse atoms sufficiently to corrupt designated roles. The only lateral conclusion I can draw is processed carbons are the major problem. From the healthcare perspective, certain other invasive unprocessed natural residues do cause viruses, but it is those that have been “manufactured” (for lack of better terminology) which specifically promulgate symptoms resulting in cancers. Fossilisation is a raw form of manufacturing, so corresponding product emissions should be regarded as topically hazardous, whereas smoke from drift firewood is most likely therapeutic.
 The cordial mistake everyone (including devout scientists) makes is to presume mechanisms that permit existence are flawlessly and fairly erred in favour of man. Per this “reasoning” man, though mortal, would be God-in-the-flesh but for vices. Expanding the view, insignificantly minute particles are beyond control and ignored because they are also above control. Consequentially, the truth, of course, could not be further derelict. In my book “The Beauty of Existence Decoded” I lay claim that via the expressively receptive qualities of atoms, everything “lives” regardless of whether it is categorised as inanimate or animate. Ultimately, a single particle domineers to effectively preside over the group in the formulation of “soul”. Even so hierarchical interaction is rather complex below the tip of the pyramid. Following in the footsteps of their cultivated souls and their perceptive human bodies, atoms are sometimes presented with drastic determining choices. These forks in the road dictate vital decisions that will precede reactive judgements.
The cordial mistake everyone (including devout scientists) makes is to presume mechanisms that permit existence are flawlessly and fairly erred in favour of man. Per this “reasoning” man, though mortal, would be God-in-the-flesh but for vices. Expanding the view, insignificantly minute particles are beyond control and ignored because they are also above control. Consequentially, the truth, of course, could not be further derelict. In my book “The Beauty of Existence Decoded” I lay claim that via the expressively receptive qualities of atoms, everything “lives” regardless of whether it is categorised as inanimate or animate. Ultimately, a single particle domineers to effectively preside over the group in the formulation of “soul”. Even so hierarchical interaction is rather complex below the tip of the pyramid. Following in the footsteps of their cultivated souls and their perceptive human bodies, atoms are sometimes presented with drastic determining choices. These forks in the road dictate vital decisions that will precede reactive judgements.
 The closer you edge toward divinity the higher you climb up the spiritual scale. Atoms are found at the very pinnacle, because each portal (the nucleus) spans all dimensions and all time. Clumsy human comparatively only receives a fraction of this resonance, because of his puny bandwidth range. Inadequate perception cannot disguise the fact that the quantum layer operates at the highest level of divinity. Therefore, the dramatic consequence is doomed to shock those that swear by their systemisation. The mind and all attributed spiritual manifestations (including the so-called higher self) are part and parcel of the exact same delivery mechanism. Here my earlier mention of the importance of a balanced libido in respect to good health should begin to gel. Wishes (needs) of the spiritual self, mind and physical body travel down identical inter-connected streams. With respect to cancers, because the body is made of carbon, atoms somehow become disoriented by certain types of invaders (namely the processed molecules I highlighted earlier).
The closer you edge toward divinity the higher you climb up the spiritual scale. Atoms are found at the very pinnacle, because each portal (the nucleus) spans all dimensions and all time. Clumsy human comparatively only receives a fraction of this resonance, because of his puny bandwidth range. Inadequate perception cannot disguise the fact that the quantum layer operates at the highest level of divinity. Therefore, the dramatic consequence is doomed to shock those that swear by their systemisation. The mind and all attributed spiritual manifestations (including the so-called higher self) are part and parcel of the exact same delivery mechanism. Here my earlier mention of the importance of a balanced libido in respect to good health should begin to gel. Wishes (needs) of the spiritual self, mind and physical body travel down identical inter-connected streams. With respect to cancers, because the body is made of carbon, atoms somehow become disoriented by certain types of invaders (namely the processed molecules I highlighted earlier).
There is only one logical explanation for all this. That which is distinctively recognised is defined and categorised by its recognition. Taking the analogy a step further; do rogue processed carbons disable quantum energetic resonance to such an extent that associated products lose their lustre? An ardent numismatist wouldn’t discard a rare and otherwise desirable ancient coin because of its worn patina. Perhaps one day he will learn a new technique to aid verification of identification. As everything that enters the body is assimilated or expelled, anomalous indistinct invaders “pending categorisation” are marked but not rejected. These new unknown parts correspondingly “belong to” but are also “separate of” the body.
 Extraneously matter is always immediately targeted by agents designated to protect the body. Invading processed carbons would follow a path of being combined with other genetic materials in the creation of special cells that specifically identify this syndrome. However, when the libido becomes imbalanced, focus is prioritised elsewhere, leaving alien components to their own devices. The special cells consequentially develop at odds with the body because they have been corrupted by processed carbons that have no quantum interest in precise developmental strategy. At some point in this metabolic growth evolution, Royal Rife was able to identify malignance with his electron microscope. I think I have successfully gone “full circle” (so to speak) by way of explanation.
Extraneously matter is always immediately targeted by agents designated to protect the body. Invading processed carbons would follow a path of being combined with other genetic materials in the creation of special cells that specifically identify this syndrome. However, when the libido becomes imbalanced, focus is prioritised elsewhere, leaving alien components to their own devices. The special cells consequentially develop at odds with the body because they have been corrupted by processed carbons that have no quantum interest in precise developmental strategy. At some point in this metabolic growth evolution, Royal Rife was able to identify malignance with his electron microscope. I think I have successfully gone “full circle” (so to speak) by way of explanation.
In my opening address I made the following statement:
“…vacuum precipitates with ceaseless and often dishonourably prejudicial accusations supporting “causes” to the detriment of reason. Whether that be specifically anti-vaccines, cigarettes or generally against ambiguous “carcinogens” depends on the vigour of focused political interests.”
It is time to elaborate on this in a slightly contradictory fashion. My umbrage was directed at those destined to confuse with ignorance and not against philosophies supporting cases that define toxins as causing agents of various cancers. Processed tobacco smoke, certain vaccines, pesticides most definitely are the strategic proxies that trigger cancers. These, in context, are an imperative supplementary part of the puzzle. Obviously cancers do not spring up merely because of depression or other ego imbalances. Libido insufficiency impresses an environmental shift whereby problems that had been routinely dealt with prior now spin out of kilter. Per that capacity, once dormant vaccine components, for instance, spring to life.
 In many cases (perhaps all), the agent would cause multiple issues. Focusing on vaccines again, perhaps an immediate adverse effect (to the libido) would be to bring on (express as) fevers, nausea and so on. Symptoms clear up, but the libido is still undetectably impaired. Much time ensues before cancers reach the stage of being visible and then blame game begins. Blame is unnecessary when separate root causes, causing agents and triggers have been clearly defined. That is by virtue of the fact there is only one truth (whereas the potential for propagandas is near limitless). Truth, if the truth be known, is hallowed.
In many cases (perhaps all), the agent would cause multiple issues. Focusing on vaccines again, perhaps an immediate adverse effect (to the libido) would be to bring on (express as) fevers, nausea and so on. Symptoms clear up, but the libido is still undetectably impaired. Much time ensues before cancers reach the stage of being visible and then blame game begins. Blame is unnecessary when separate root causes, causing agents and triggers have been clearly defined. That is by virtue of the fact there is only one truth (whereas the potential for propagandas is near limitless). Truth, if the truth be known, is hallowed.
Corporate scientists (correspondingly) have been compelled to use complexity largely for the disregard of wisdom. That is why the record has been subject to one spectacular failure after another; I exampled Chernobyl before. By extension, science view on the fundamentals that permit the identification of radiation has not altered one iota from day one. Environmental conditions do regularly change and this forces remedial adjustments to expanded theories. In some cases apparently associated symptoms dance the pas-de-pas elevating theoretical definitive causes. Of course, most prognoses are incorrect and that is predominantly why science continually trips itself up over and over.
 Personally, I am fascinated by the concept “cloud nine”. Nothing will encourage me to travel Huxley’s brave but tainted discovery path, but I am intrigued as to the physical value of altered states. Is this a (and perhaps the only) method of discerning the keys to the mechanics of the quantum layer? It seems to me that altered states is one of the few potential watersheds that might definitively transform science and formulations that permeate critical thinking. Could imagination act as a temporary bridge? If the mind was separate of the body (alien, if you will) that would explain universal magnetism towards materialism. An alien contained by physicality would plausibly obsess over laws “for survival”. Therefore, by deduction, rule lacking imagination becomes mind’s natural state.
Personally, I am fascinated by the concept “cloud nine”. Nothing will encourage me to travel Huxley’s brave but tainted discovery path, but I am intrigued as to the physical value of altered states. Is this a (and perhaps the only) method of discerning the keys to the mechanics of the quantum layer? It seems to me that altered states is one of the few potential watersheds that might definitively transform science and formulations that permeate critical thinking. Could imagination act as a temporary bridge? If the mind was separate of the body (alien, if you will) that would explain universal magnetism towards materialism. An alien contained by physicality would plausibly obsess over laws “for survival”. Therefore, by deduction, rule lacking imagination becomes mind’s natural state.
Imagine that, coming clean on cancer only simply requires imagination.
















